[JavaScript] Element를 저장 및 불러오기
[JavaScript] Element를 저장 및 불러오기

이 글은 Range 값을 저장하기 위해 코드를 작성하다가 localStorage에 Element 정보가 저장되지 않아서 이를 해결하기 위한 트러블 슈팅을 정리한 글입니다.
TLDR;
Range 값을 저장 후 불러오고 싶은데, Element 값을 저장할 수 없었습니다. JSON.stringify를 사용해서 Element를 문자열 값으로 수정하려 하더라도 빈 객체가 반환되었습니다.

이를 해결하기 위한 방법을 알아보던 중, 페이지의 Element에 data-key를 모두 설정한 뒤, 해당 data-key를 저장하는 방법도 있었습니다. 하지만, 이 방법의 경우 페이지 내에서 변경이 일어난다면 data-key 값이 이전과 같을 것이라 보장할 수 없습니다.
해당 문제를 해결하기 위해 XPath를 사용해 Element 값을 저장 및 불러올 수 있습니다.
Table of Contents
- Element를 저장하기
- XPath
- XPath의 문법
- 절대 경로와 상대 경로
- 동일한 Element Tag name이 존재하는 경우
- text node 구하기
- XPath Class
Element를 저장하기
localStorage API는 문자열로 데이터를 저장합니다. 그렇다면 HTML 항목을 저장하기 위해서는 어떻게 해야 할까요??
만약, HTML의 값을 저장한다면 innerHTML 속성으로 HTML 내부 값을 문자열로 반환해 목록을 가져온 뒤 저장할 수 있습니다. 그리고 대부분의 경우에는 이 방법으로 내부 값을 저장하고 가져오는 방법으로 처리할 수 있습니다.
하지만, 하이라이터를 만든다고 하면 하이라이팅된 범위를 저장하기 위해 Range 객체를 저장해야 합니다. 그리고 이 Range 객체의 값 중 startContainer, endContainer 값을 저장해야 하는데, 이 값은 Node로, JSON.stringify 등과 같은 메소드를 사용해서 문자열 값으로 변환할 수 없습니다.
const range = document.createRange();
const p = document.getElementById("p1");
range.selectNode(p1);
console.log(JSON.stringify(range.startContainer)); // {}XPath (XML Path Language)
XPath는 XML 문서의 특정 부분의 위치를 찾을 때 사용하는 언어입니다.
윈도우에서 탐색기는 폴더의 주소를 전달받아서 해당 주소에 있는 파일을 보여줍니다. 이러한 주소 값을 이용해 우리는 원하는 파일을 찾을 수 있습니다. XPath에서도 이와 같이 원하는 태그나 속성을 찾기 위해 path 문법이 존재합니다.
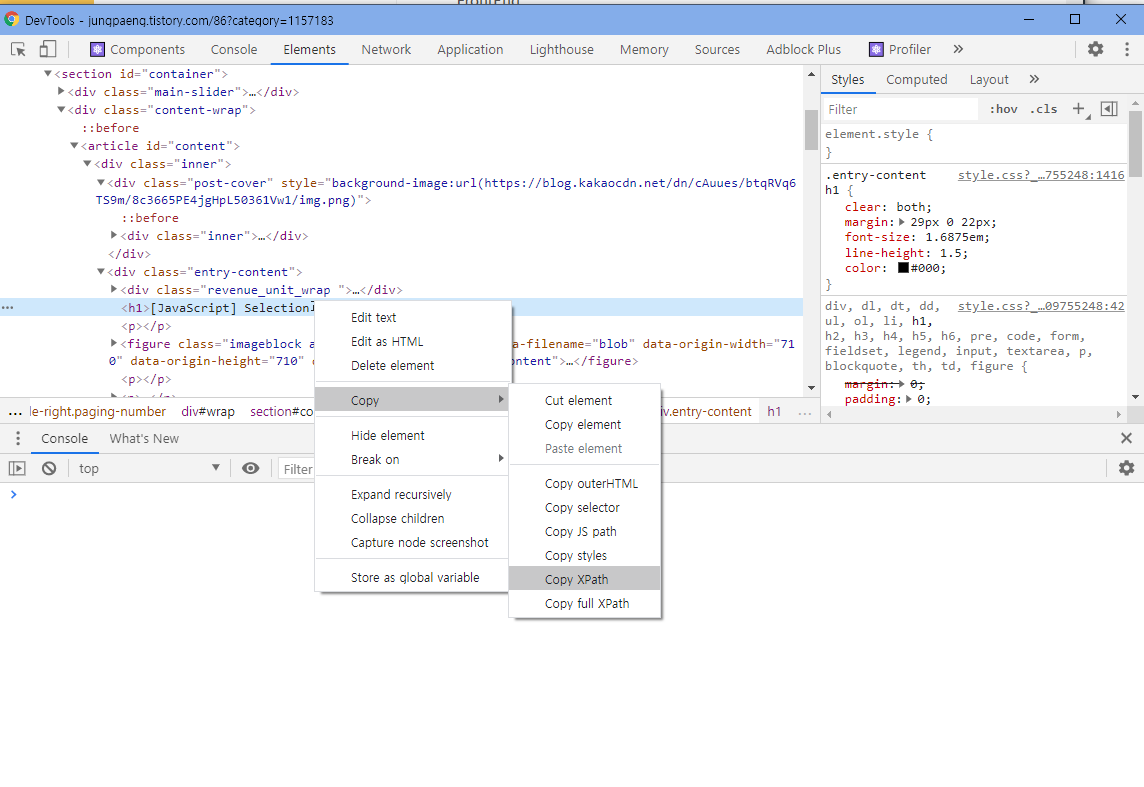
Chrome DevTools 에서 Element를 우클릭하면 XPath를 복사할 수 있습니다.
//*[@id="content"]/div[1]/div[2]/h1XPath의 문법
XPath를 생성하기 위한 구문은 다음과 같습니다.
//tagname[@attribute='value']- // : 현재 노드를 선택
- Tagname : 특정 노드의 Tagname
- @ : 속성을 선택
- Attribute : 노드의 속성 이름
- Value : 노드의 속성 값
절대 경로와 상대 경로
절대 경로
절대 경로로 XPath를 탐색하는 것은 최상위 노드부터 탐색하는 방법입니다. 절대 경로로 탐색하는 것의 단점은 루트 노드와 탐색하는 노드 사이에 변화가 있다면 탐색이 실패할 수 있다는 것입니다.
html/body/div[1]/section/h1상대 경로
상대 경로로 XPath를 탐색한다면 HTML DOM 구조의 중간부터 시작할 수 있습니다. 상대 경로로 탐색하기 위해서는 XPath가 //로 시작해야 합니다.
HTML DOM 구조의 중간부터 시작할 수 있으므로 절대 경로로 작성하는 것보다 XPath의 길이가 짧아집니다.
//*[@id="content"]/div[1]/div[2]/h1위 XPath는 #content Element부터 탐색을 시작하는 XPath 입니다.
동일한 Element Tag name이 존재하는 경우
<html>
<body>
<section id="sec">
<div>
<p>Text 1</p>
</div>
<div>
<p>Text 2</p>
</div>
</section>
</body>
</html>위와 같은 HTML 구조에서 Text 1을 감싸고 있는 p 태그의 XPath를 구하고 싶다면 어떻게 해야 할까요?
XPath의 NodeName은 기본적으로 모든 NodeName을 불러옵니다. 그리고 원하는 것만 찾을 수 있도록 []를 제공합니다. 아래와 같이 작성한다면 첫 번째 div를 선택할 수 있습니다.
//section[@id="sec"]/div[1]text node 구하기
마지막으로, Text 노드를 찾기 위해서 text()를 사용할 수 있습니다. text node는 엘리먼트 노드 내에 존재하기 때문에 엘리먼트 노드 뒤에 위치해야 합니다.
아래 XPath는 모든 title 태그 내의 Text 노드를 추출합니다.
//title/text()XPath Class
Node를 받아서 XPath를 구하는 메소드를 포함하고 있는 XPath 클래스를 작성해보도록 하겠습니다.
class XPath {
public getXPathFromNode = (node: Node | Element) => {
const paths: string[] = [];
while ([Node.ELEMENT_NODE, Node.TEXT_NODE].includes(node.nodeType)) {
let index = 0;
if ((node as Element).id) {
const selector = `[id="${(node as Element).id}"]`;
const { length } = document.querySelectorAll(selector);
if (length === 1) {
// 동일한 id 값이 하나인 경우에만 Element를 상대 경로로 작성합니다.
paths.splice(0, 0, `/*[@id="${(node as Element).id}"][1]`);
break;
}
}
for (let sibling = node.previousSibling; sibling; sibling = sibling.previousSibling) {
if (sibling.nodeType === Node.DOCUMENT_TYPE_NODE) continue;
if (sibling.nodeName === node.nodeName) index++;
}
// TEXT_NODE 인 경우, `text()`를 반환합니다.
const tagName = node.nodeType === Node.ELEMENT_NODE ? node.nodeName.toLowerCase() : 'text()';
const pathIndex = index ? `[${index + 1}]` : '';
paths.splice(0, 0, tagName + pathIndex);
// 식별 가능한 노드를 찾을 때까지 부모 노드를 탐색합니다.
node = node.parentNode;
}
return paths.length ? `/${paths.join('/')}` : null;
};
}위 클래스의 getXPathFromNode 메소드를 간단히 설명하면 다음과 같습니다.
node를 전달받아서 id 값을 갖고 있는지 확인합니다.- id 값을 갖고 있다면 식별 가능하므로 상대 경로로 XPath를 생성한 뒤, 반복문을 종료합니다.
- id 값을 찾을 수 없는 경우에는
previousSibling값을 확인합니다.- sibling 값은 동일한 부모를 갖고 있는 즉, 형제 노드를 확인하는 것입니다.
- 선택된 노드보다 이전에 형제 노드가 존재하는 경우, index 값을 1씩 늘려서 index 값을 구합니다.
- 선택된 노드가
ELEMENT_NODE라면node.nodeName을 반환하고,TEXT_NODE라면text()를 반환합니다. - 부모 노드를 위와 같은 과정을 거칩니다.
위와 같은 절차를 거쳐서 Element의 XPath 값을 구할 수 있습니다. XPath를 Element로 변환하는 것은 XPathEvaluator 클래스를 사용해 쉽게 작업할 수 있습니다.
const xPath = '...';
const evaluator = new XPathEvaluator();
const result = evaluator.evaluate(
xPath,
document.documentElement,
null,
XPathResult.FIRST_ORDERED_NODE_TYPE,
null
);'Advanced > JavaScript' 카테고리의 다른 글
| [JavaScript] Virtual DOM 만들기 (2) | 2021.01.26 |
|---|---|
| [JavaScript] 바닐라 자바스크립트로 웹 컴포넌트 만들기 (0) | 2021.01.25 |
| [JavaScript] Selection과 Range (0) | 2020.12.29 |
| [JavaScript] 캘린더 만들기 - 한 주 구하기 (0) | 2020.12.20 |
| [JavaScript] 가변 인자 함수 (1) | 2020.11.16 |